How Devs aggregate data in SQL
In SQL, the `GROUP BY` and `SELECT` statements are used together to aggregate data based on certain criteria. The `GROUP BY` clause groups rows that have the same values in specified columns into summary rows, and the `SELECT` statement is then used to retrieve the aggregated results. Here’s a brief explanation of each:
1. GROUP BY Clause:
The `GROUP BY` clause is used to group rows that have the same values in specified columns into summary rows, often for the purpose of applying aggregate functions.
Syntax:
```sql SELECT column1, aggregate_function(column2)
FROM table
GROUP BY column1;```Example: Suppose you have a table called `sales` with columns `product`, `category`, and `amount`. You want to find the total sales for each product category.
```sql
SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category;
```
This query groups the rows by the `category` column and calculates the total sales (`SUM(amount)`) for each category.
2. SELECT Statement with Aggregate Functions:
The `SELECT` statement is used to specify the columns you want to include in the result set and apply aggregate functions to those columns.
Aggregate functions perform calculations on a set of values and return a single value. Common aggregate functions include `SUM`, `AVG`, `COUNT`, `MIN`, and `MAX`.
Example: Continuing with the previous example, you can use the `SELECT` statement to retrieve the aggregated results.
```sql SELECT category, SUM(amount) AS total_sales
FROM sales
GROUP BY category;```The result might look like:
| Category | Total Sales |
| Electronics | 1500 |
| Clothing | 1200 |
| Books | 800 |
The `SELECT` statement retrieves the `category` column and the calculated `total_sales` using the `SUM` aggregate function.
These statements together allow you to group data based on specific criteria and perform aggregate calculations on those groups. The result is a summary of the data that provides insights into various aspects, such as total sales, average values, or counts, depending on the chosen aggregate functions.
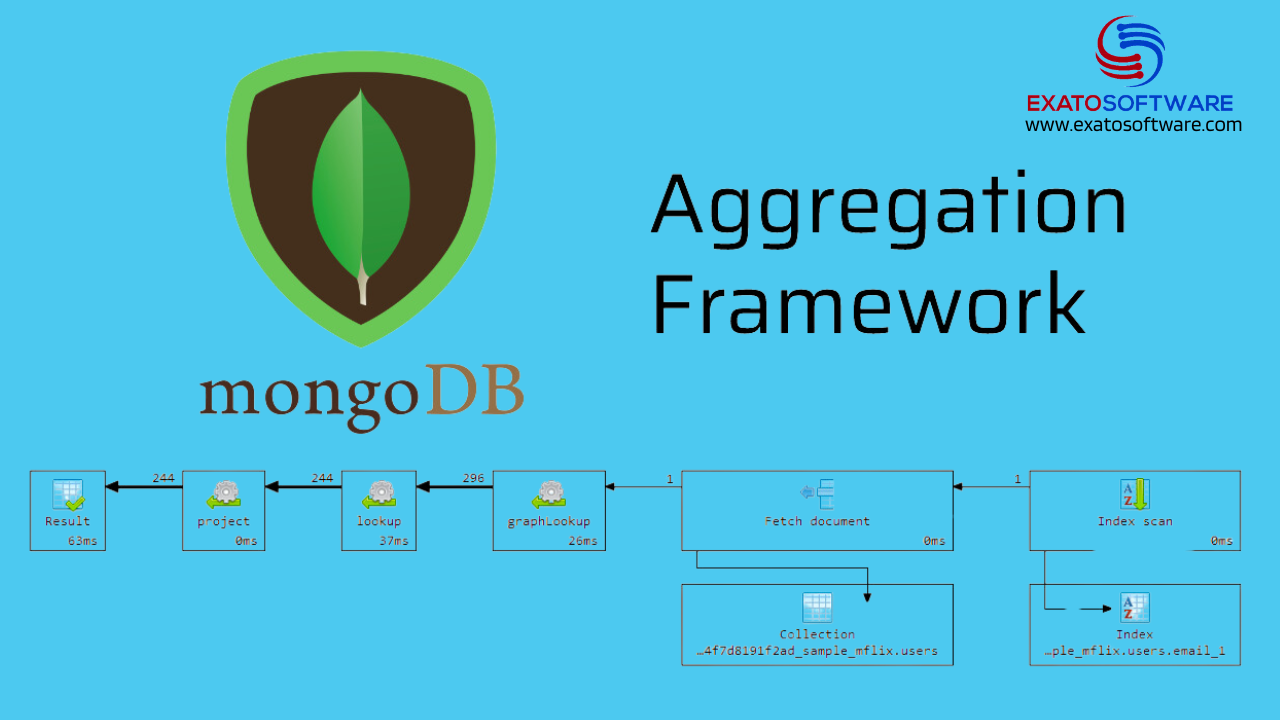
Aggregation Framework in MongoDB
The Aggregation Framework in MongoDB is a powerful tool for performing data transformation and analysis operations on documents within a collection. It allows you to process and aggregate data in various ways, such as filtering, grouping, sorting, and projecting, similar to SQL’s GROUP BY and SELECT statements. The Aggregation Framework is particularly useful for complex data manipulations and reporting.
Key components and concepts of the Aggregation Framework
1. Pipeline:
The aggregation framework operates on data using a concept called a pipeline. A pipeline is an ordered sequence of stages, where each stage performs a specific operation on the data.
Stages are applied sequentially to the input documents, with the output of one stage becoming the input for the next.
2. Stages:
Each stage in the aggregation pipeline represents a specific operation or transformation. Some common stages include `$match`, `$group`, `$project`, `$sort`, `$limit`, and `$unwind`.
Stages allow you to filter, group, project, and manipulate data in various ways.
3. Operators:
Aggregation operators are used within stages to perform specific operations on the data. These operators include arithmetic expressions, array expressions, comparison operators, and more.
Examples of aggregation operators include `$sum`, `$avg`, `$group`, `$project`, `$match`, and `$sort`.
4. Expression Language:
The Aggregation Framework uses a powerful expression language that allows you to create complex expressions to perform calculations and transformations on data.
Expressions can be used to reference fields, apply operators, and create new computed fields.
Here’s a simple example of an aggregation pipeline:
```javascript
db.sales.aggregate([
{
$match: { date: { $gte: ISODate("2023-01-01"), $lt: ISODate("2023-02-01") } }
},
{
$group: {
_id: "$product",
totalSales: { $sum: "$amount" },
averagePrice: { $avg: "$price" }
}
},
{
$sort: { totalSales: -1 }
},
{
$project: {
_id: 0,
product: "$_id",
totalSales: 1,
averagePrice: 1
}
},
{
$limit: 10
}
]);
```
In this example, the aggregation pipeline does the following:
`$match`: Filters documents based on the date range.
`$group`: Groups documents by product and calculates total sales and average price for each product.
`$sort`: Sorts the results in descending order of total sales.
`$project`: Projects a subset of fields and renames the `_id` field to “product.”
`$limit`: Limits the output to the top 10 results.
This is a simplified example, and the Aggregation Framework provides a wide range of stages and operators to handle more complex scenarios, including nested documents, array manipulation, and text search. It’s a powerful tool for performing data transformations and analysis directly within MongoDB.
Aggregation in SQL and Aggregation framework in MongoDB: Comparison
Comparing the MongoDB Aggregation Framework with the SQL `GROUP BY` and `SELECT` statement for aggregation depends on the context, use case, and specific requirements of your application. Here are some considerations for both:
MongoDB Aggregation Framework
Pros
1. Flexibility:
The MongoDB Aggregation Framework is highly flexible and capable of handling complex data transformations and manipulations.
2. Schema Flexibility:
MongoDB’s schema-less nature allows for dynamic aggregation on documents with varying structures within the same collection.
3. Pipeline Stages:
The Aggregation Framework operates on a pipeline with various stages, allowing you to chain together different operations for comprehensive data processing.
4. Rich Set of Operators:
MongoDB provides a rich set of aggregation operators that cover a wide range of operations, including filtering, grouping, sorting, projecting, and more.
5. Native JSON Format:
The output of MongoDB’s Aggregation Framework is in a native JSON-like format (BSON), making it easy to work with in applications.
Cons:
1. Learning Curve:
The Aggregation Framework may have a steeper learning curve, especially for those new to MongoDB or NoSQL databases.
2. Performance Considerations:
While MongoDB provides powerful aggregation capabilities, performance considerations become crucial, especially for large datasets.
SQL `GROUP BY` and `SELECT` Statement
Pros:
1. Widely Known:
SQL is a widely known and used language for querying relational databases. Many developers and data analysts are familiar with SQL syntax.
2. Standardized Syntax:
SQL follows a standardized syntax, making it consistent across different database systems.
3. Optimized Query Execution:
Relational databases often come with query optimization features, and SQL engines are well-optimized for executing queries efficiently.
4. Mature Ecosystem:
SQL has a mature ecosystem with various tools and libraries for reporting, analysis, and integration.
Cons:
1. Rigid Schema:
Relational databases enforce a rigid schema, and any changes to the schema may require careful planning and, in some cases, downtime.
2. Limited Document Support:
SQL databases are not designed to handle documents with nested structures as naturally as MongoDB. Complex relationships may require multiple tables and joins.
3. Joins Complexity:
For scenarios involving complex relationships, the need for joins can increase query complexity and potentially impact performance.
Conclusion
The choice between MongoDB’s Aggregation Framework and SQL `GROUP BY` and `SELECT` statements depends on factors such as the nature of your data, the level of flexibility required, the size of your dataset, and the existing skill set of your development team. Both approaches have their strengths and weaknesses, and the best choice often depends on the specific use case and the overall architecture of your application.